Del ácido desoxirribonucleico (ADN) a las proteínas
3. La traducción de la información (del ARNm a proteína)
La traducción del lenguaje de los ácidos nucleicos al lenguaje de las proteínas permite el montaje de la cadena de aminoácidos en un cierto orden. De este modo, se establece en la célula un flujo de información genética que sigue una dirección única: del ADN al ARN, del ARN al péptido.
Una excepción a esta regla son los retrovirus, cuyo material hereditario es el ARN, porque
cuentan con una enzima (transcriptasa reversa) que les permite transcribir la información
en sentido ARN-ADN.
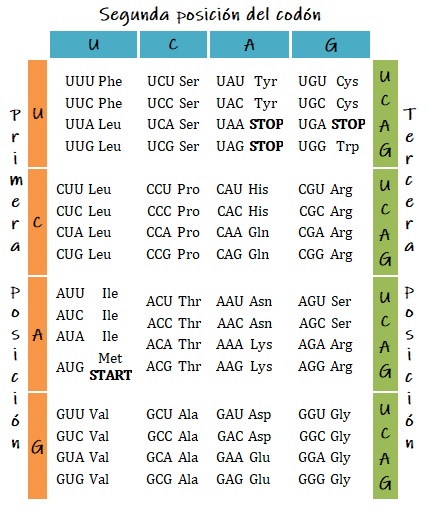
La tabla nos muestra cuáles aminoácidos se corresponden con los diferentes codones o tripletes de bases de ARNm. Algunos son codificados por un único triplete, como el triptófano (UGG) o la metionina (AUG): otros admiten varios codones que resultan sinónimos, por ejemplo, la prolina (CCU, CCC, CCA, CCG).
El inicio de la secuencia está señalizado por AUG, el codón correspondiente a metionina, siendo este aminoácido removido posteriormente. El fin de la secuencia está señalizado por UAA, UAG o UGA, tres codones que significan stop, así como en nuestro lenguaje el punto representa el fin de una frase.
Los cambios en la secuencia de bases del ADN pueden tener como consecuencia la sustitución de un aminoácido por otro. En la beta globina humana, si GUG es sustituido por CGU, el aminoácido valina será sustituido por leucina. Pero en función de la sinonimia del código, si el triplete GUG fuera sustituido por GUA o GUC, el aminoácido codificado seguirá siendo valina. Pérdidas o adiciones de una base modifican el resto de la secuencia del péptido.
Las mutaciones puntuales corresponden a pequeños cambios de la secuencia, debidas a errores en la duplicación del ADN. Su frecuencia aumenta en presencia de algunos agentes químicos y físicos como la luz ultravioleta y los rayos X.
En resumen:
Observa el siguiente video: